Back to the base tools section.
Video section
Alternative video links:
Docker
When I found out about Docker, some years ago, I was immediatelly amazed by this tool’s abilities. I knew, that the world of software development tools, my world, had changed forever. It took me a couple of months to get used to it, and to learn how to use and build my own Docker images. This knowledge had become fundamental to me, since then.
I started asking students about their experience with Docker just a few months after I had found it myself. At that time (let’s say it could be in 2016/17), they usually knew nothing about it, they had never heard about Docker before. At the beginning, it was difficult for them to work with Docker. Once, one of my student came to me, and told me, that he had to use Docker in his job. He was amazed, how many problems were solved with just using this single piece of software.
For those reasons, I find it essential for every wanna-be developer to learn about Docker.
Therefore, I’m going to start with problem specification, then I’ll move to present Docker, as a solution to the problem.
Problem
Let’s start with the actual problem. I’m going to describe four different cases. Then, we’ll try to conclude them all, so enyone should be sure, what the actual problem is. Finally, I’ll try to explain, how the problem can be solved, in real-life.
Case 1. My colleague wrote some unit tests. I tried to run them, but I failed. I asked him for help. It turned out, that even he wasn’t able to run them, on my machine. Well, it worked on his machine, and also on some other machines, but not on mine one. I could only wonder, whether the tests would run on the production server.
(BTW, running the tests on my computer wasn’t so important, since I wasn’t the part of the PHP team, so the inability to run them hadn’t affected the project’s results.)
Case 2. I wrote some software, using Node.js, and some libraries. It worked without any problems on my machine. When I handed it out to my students (all of them were supposed to make a project, based on this software), most of them had issues running it. Well, I made at least one mistake: I hadn’t froze the used dependencies. But it also turned out, that newer versions of Node.js, and some tools, worked in a different way. As the result, the software could be compiled only on my machine, the one I developed it on in the first place.
Case 3. I don’t like Matlab (and, in general, using proprietary software in education), so I wrote a simple Python library to implement genetic and evolutionary algorithms. Using the library, students were able to pass an exercise in about two hours (some of them even faster). It Just Worked ©, for many years. Until, some year, someone (a student) told me, that it stopped to work. Just out of the blue, the library stopped to work. The weird thing was that the library worked fine on my machine, and on many other machines, but refused to work on some machines in the computer laboratory, where students had their classes. Having an hour (or two) of time, I decided to take a look at the problem. I have found the problem cause in about 5 minutes. My library was written for Python 2.7, and someone installed a newer version of Python (3.x) on some machines. To fix the problem, I had to change just one line of code.
Case 4. Before the stackage repository was created, I had many headaches trying to compile various Haskell projects. I have no doubts, that they all worked on their developers machines, they just refused to compile on my own. You see, the problem is to have particular versions of many libraries (stackage repository make it possible) compiled with particular version of GHC (the Haskell compiler). Try to guess, whether the GHC version that comes with your distro is the same, as the required one? And how can you use the particular version to compile one project, while a very different version to compile something else? Set up such specific environment can be a real challenge.
(The real problem is about using such versions of libraries, which can be compiled on some particular compiler version.)
Of course, I refer to Linux distributions problems. I cannot tell you anything about Windows development, since I haven’t been using Windows for many years now. Referring to many stories, that I have found on the net, though, makes me think that Linux is much more friendly for development, than Windows. So I suppose, that on Windows the mentioned problems also occur, probably even they are more difficult to solve.
Well, I guess you can see the problem: it works on my machine.
Of course, the goal is not to having software working on every possible machine. In real-life situations, we always target some specific machines, or platforms. For example, when we develop web applications, we can assume, that on the server particular version of PHP, and particular version of MySQL are used, and on the frontend we can assume that our application should work on Chrome, or Edge, starting from some particular versions, up.
I’m going to focus rather on server-side aspects.
The source of the problem
That problem can be solved in many ways, and they are not that simple, or obvious. (If they were, it wouldn’t be a problem at all!)
Where does the problem come from? Why is it so difficult to solve in the first place?
The short answer is: since developers work in different environments, and environment affects the way software works, it causes such differences, that they can achieve different results, even for the same software. By environment, I mean the operating system (and its configuration), some kernel (and its configuration, drivers, and so on) and the installed software (also with some configuration). It all is so complex, that having exactly the same environment is (almost) impossible to achieve. Almost.
Just like people use different cars, phones and have different hobbies, they also use different computers, operating systems, and software. It won’t be very unlikely to assume, that we all work in unique environments, used just by ourselves. Even my wife, who works on the same computer, uses different web browsers, and has installed different add-ons (actually, I have them installed for her), so it is possible (and highly probable), that her browser works in a different way to mine.
What is this environment?
Let’s take a closer look to this environment. What it is, actually? Each computer is composed of some components, like CPU, memory, disks, and so on. They all are used directly by operating system’s kernel, that provides some uniform interface for all other software. What we call “operating system”, is some base software, installed along with the kernel, that provides base services. Then, we can use other applications, which make use of both the kernel, and the OS. All those components can be different, and work in different ways, even when provided with the same input. And most of them also require some configuration. Guess what: users usually have their machines configured in different ways.
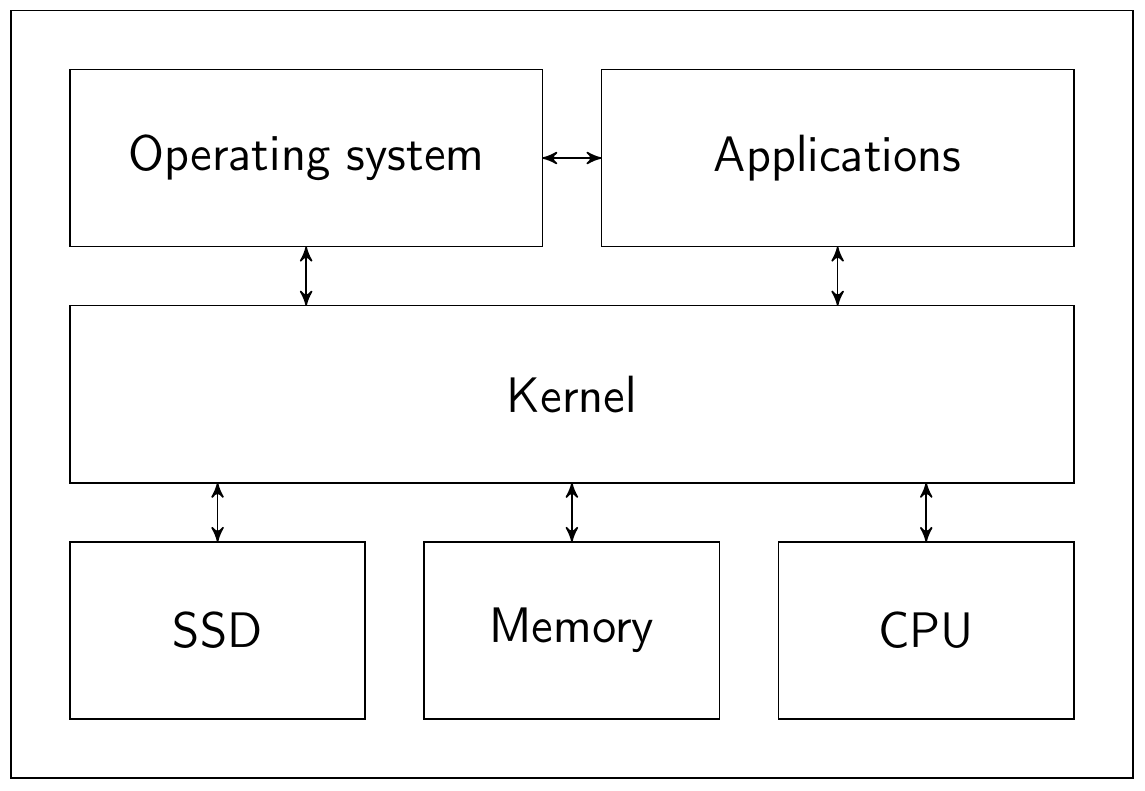
As you can see, the problem of working environment, is real, and cannot be solved in some simple way.
The real question is: what can be done about it?
Let’s start with the simple fact, that the problem cannot be solved by merely controlling (or trying to control) all developer’s machines (and whole environments). First of all, developers usually work on various computers. Even if we somehow could make them all to use machine of some particular type (the same hardware, for everyone), the amount of configuration options would be so high, that the task of having exactly the same environment in all places would be impossible to fulfill. That’s not the way - controlling is not the answer (and not only in development, btw).
The solution would be to use some artificial, or “virtual” environment, instead. Since environment is very complex, probably some specialized software would be needed to manage it. Developers would then have to use the software, just like they use IDEs, compilers and other tools to do their jobs.
In fact, there is such software, and it can be used. I’d even say, that it should be used.
There are many ways, such a software can work:
- it can emulate the whole hardware, thus allowing user to emulate having a properly configured operating system, and development (or production) software to work with
-
it can create so-called virtual machines (VMs), that emulate some computer systems (not neccessarily only hardware)
Example of such software is QEMU. - finally, it can make use of the operating system’s kernel, and manage the separate user spaces, where a process (or many processes) are run. This technique is called containerization, and it is more lightweight in comparison to virtual machines.
Example of such software is Docker.
I should made it clear: I’m not an expert in the field of VMs, or containers. I used to use VMs, and I use containers, to solve the mentioned problem, all the time. So, my perspective is point of view of a regular user.
Comparing VMs to containers, I would say that VMs are more heavy. In general, they require more resources (memory, CPU power) to run. The cause is that they emulate hardware (at least to some extent). This emulation has its cost, in this case in both resources, and speed. Containers do not emulate anything. They just use the OS kernel, and replace everything else (operating system, and software), so they need less resources, and they run much faster (more efficient), than VMs.
The setup process of VM is, usually, very complex. You have to install a whole OS inside it, and configure it properly. Comparing containers to VMs, their setup process can be complex, or quite simple. It all depends on particular case, used software, and user’s needs. In the incoming materials, I’m going to show you, that using Docker is quite simple (at least in comparison to using VMs).
Comments